Source: 01 CUDA C Basics
What is CUDA?
CUDA(Compute Unified Device Architecture)는 NVIDIA의 병렬 컴퓨팅 플랫폼이자 프로그래밍 모델(SIMT)이다. GPU를 그래픽 전용이 아닌 범용 연산 장치(GPGPU)로 쓸 수 있게 해주는 C/C++ 확장이며, 2007년 처음 공개되어 지금까지 딥러닝 인프라의 사실상 표준이 됐다.
CUDA라는 것은 정확히 무엇일까? 그리고 현용 모델들을 구축할 때 사용되는 PyTorch와 무슨 관계인걸까? 알아보기 전에 계층화된 피라미드부터 알아가는 것이 좋을 거 같다.
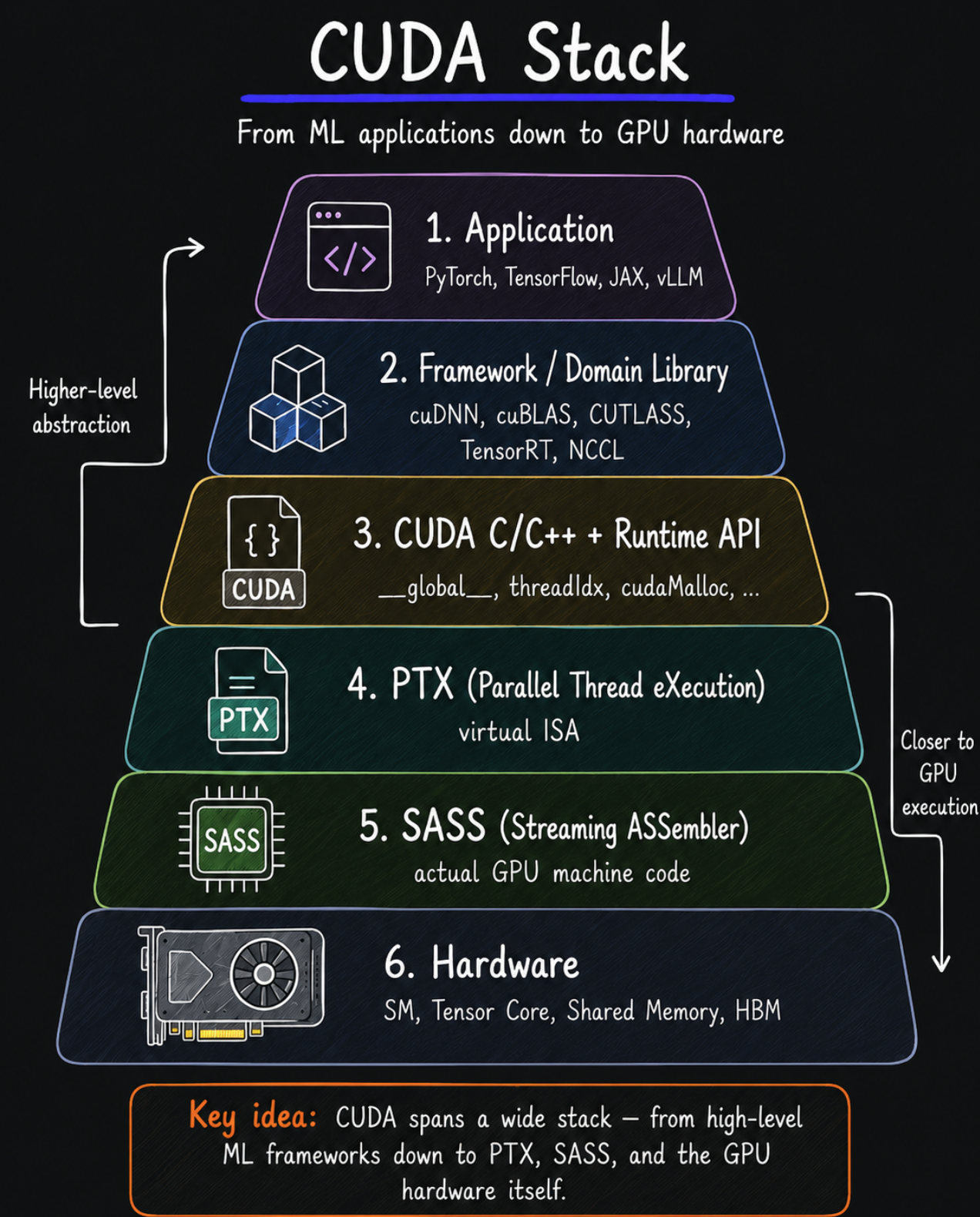
CUDA는 단 한 레이어에만 국한되지 않고 3~5번 레이어를 묶은 stack 그 자체를 이야기한다.
| 레이어 | 역할 |
|---|---|
| CUDA C/C++ | 개발자가 직접 쓰는 프로그래밍 모델. __global__, threadIdx, Grid/Block/Thread 추상화 |
| CUDA Runtime API | cudaMalloc, cudaMemcpy, 커널 launch 등 |
| nvcc | 위 코드를 PTX로 컴파일하는 NVIDIA 컴파일러 |
| PTX | 가상 ISA. 세대 간 호환성 담당 (Volta 코드를 Hopper에서도 돌게) |
| SASS | PTX를 실제 GPU별로 JIT 컴파일한 머신코드. 아키텍처마다 다름 |
GPGPU
GPGPU (General-Purpose computing on GPU)는 말 그대로 GPU를 그래픽 외 범용 연산에 쓴다는 것이다. (이전까지 GPU는 딥러닝이 뜨기 전에는 폴리곤을 계산하는 그래픽 송출용으로 상당히 쓰였다.) GPGPU가 가장 많이 사용되는 분야는 아래 사진과 같다.
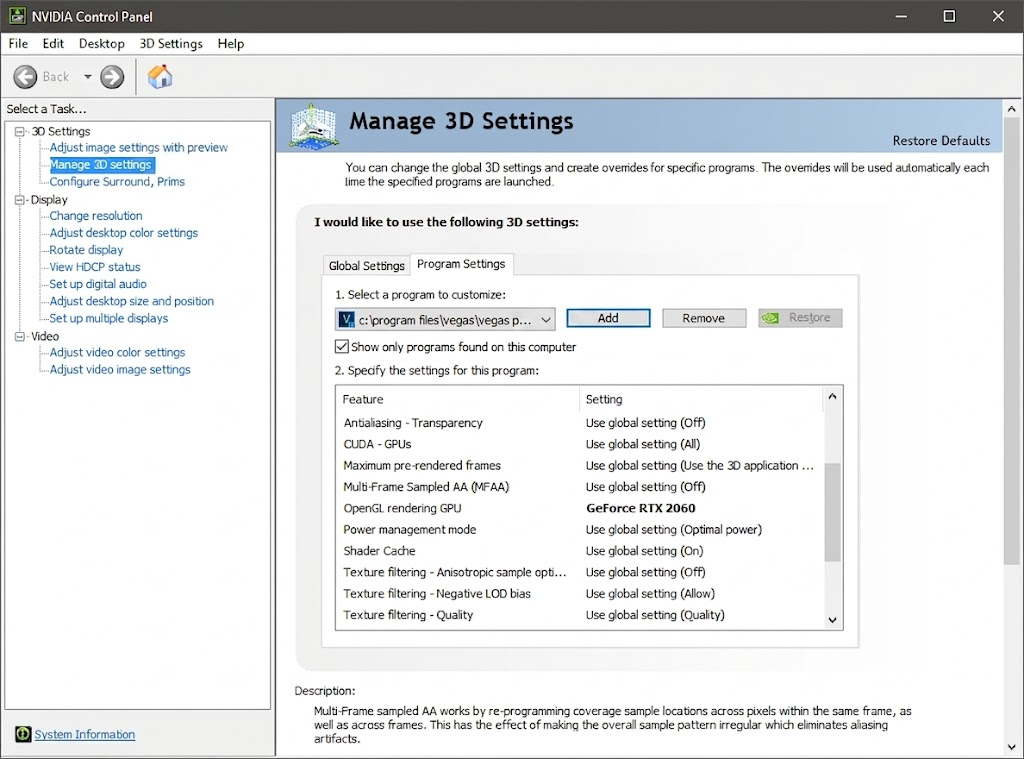
바로 영상처리 분야에서 상당히 많이 사용되고 있으며, CUDA - GPUs 같은 옵션이 보이는데, 이는 특정 프로그램이 CUDA 연산을 어느 GPU에서 돌릴지 지정하는 설정이다. 게임이 아니라 영상 편집기, 머신러닝 프레임워크 같은 GPGPU 워크로드를 위한 옵션을 말하는 것이다.
이 외 대표적인 사용처를 이야기하자면 다음이 있다.
| 워크로드 | 본질 |
|---|---|
| 영상 인코딩/필터 | 픽셀 행렬에 대한 병렬 수치 연산 |
| 딥러닝 학습/추론 | 텐서(다차원 행렬) MatMul |
| 암호화폐 채굴 | 해시 함수의 대규모 병렬 실행 |
| 과학 시뮬레이션 | 격자/입자 시스템의 병렬 업데이트 |
| 3D 렌더링 (Blender Cycles 등) | Ray 단위 병렬 계산 |
재미있는 이야기가 있지만 GPGPU를 인공신경망에 처음으로 사용한 국가가 대한민국이다.
Heterogeneous Computing
이기종 컴퓨팅(Heterogeneous Computing)이란 서로 다른 아키텍처(e.g. CPU와 GPU)가 하나의 시스템 안에서 협력하여 동작하는 방식을 말한다. CUDA 프로그래밍의 핵심은 *“모든 코드를 GPU에서 돌리는 것”*이 아니라, 연산이 무거운 부분(텐서나 행렬)들을 GPU로 오프로드(Offload)해서 GPU에서 연산처리를 진행한다.
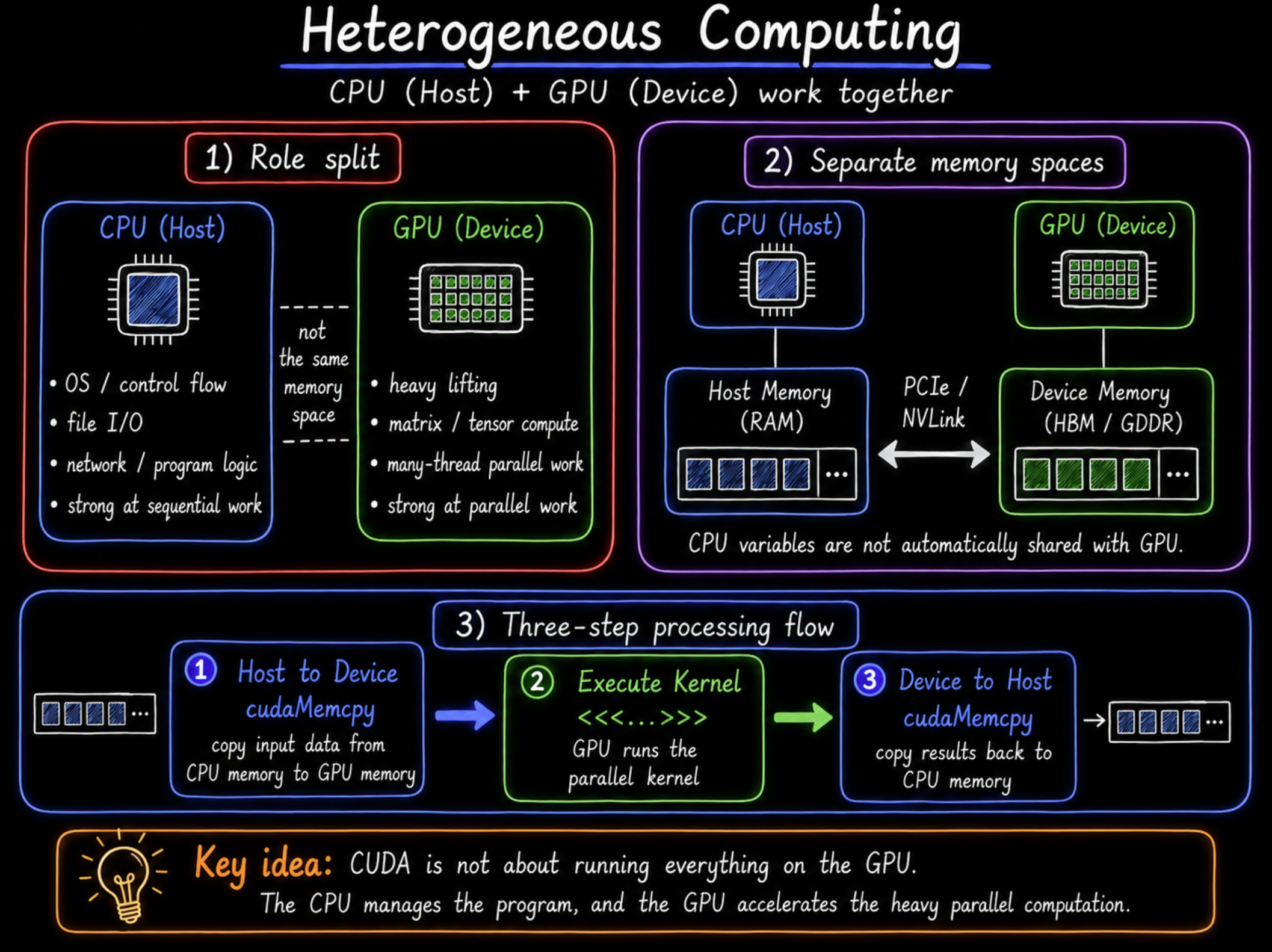
3단계 실행흐름 (DataFlow)
CPU(Host)와 GPU(Device)는 각자 독립적인 메모리 공간을 갖는다. CPU에서 만든 변수는 GPU(Device)에 공유되지 않으므로 , 개발자가 직접 데이터를 수동으로 넘겨줘야한다. 모든 CUDA 기반작성 프로그램은 메모리 단절을 극복하기 위해 아래 3단계를 거친다.

1. Host to Device — cudaMemcpy
cudaMemcpy(d_data, h_data, size, cudaMemcpyHostToDevice);
CPU 메모리의 원본 데이터를 고속 버스(PCIe, NVLink 등)를 통해 GPU 메모리로 복사한다.
2. Execute Kernel — <<<...>>>
kernel<<<gridDim, blockDim>>>(d_data);
GPU에서 병렬 처리 코드(커널)를 실행하여 실제 연산을 수행한다.
3. Device to Host — cudaMemcpy
cudaMemcpy(h_result, d_result, size, cudaMemcpyDeviceToHost);
계산이 완료된 GPU 메모리의 결과값을 다시 CPU 메모리로 가져온다.
다음을 쉽게 도식화하면, 다음과 같다.
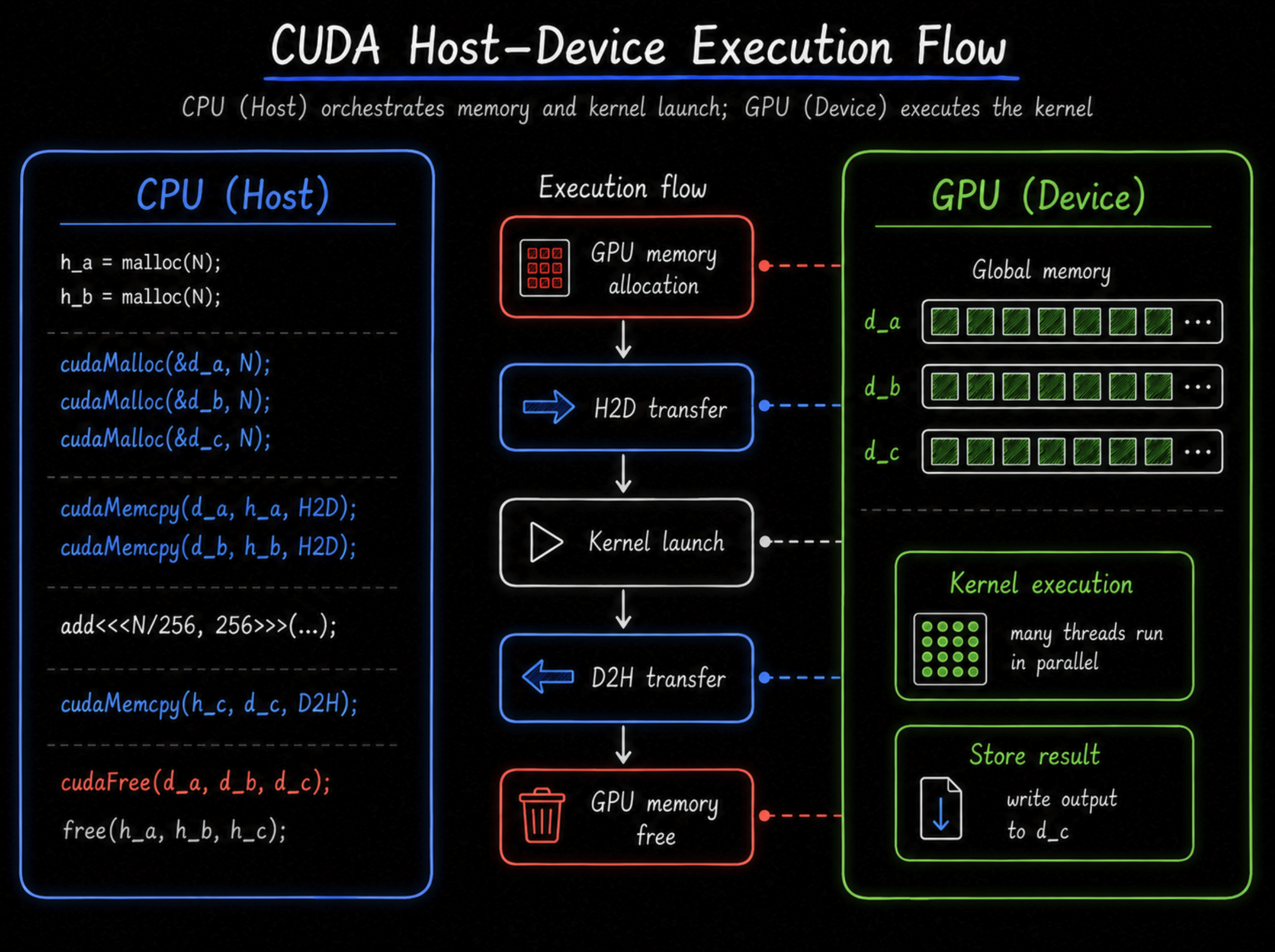
Key Takeaway: CPU와 GPU 메모리는 물리적으로 분리되어 있어 자동 공유가 안 된다. 이 3단계 패턴은 모든 CUDA 프로그램의 뼈대다. 하지만 이 3단계 자체가 CUDA 최적화의 가장 큰 병목이 된다 — 다음 섹션에서 다룬다.
하지만 이 3단계는 엄청난 병목이다(이에 대해선 다음 장에 기록해놓겠다..)
CUDA C 기본 문법과 커널(Kernel)
앞서 말한 통신 병목을 감수하고서라도 GPU에 넘길 만큼 ‘무거운 연산’이란 무엇일까? CUDA 기초에서 그 이점을 가장 직관적으로 보여주는 예제가 바로 **벡터 덧셈(Vector Addition)**이다. 각 인덱스의 계산이 서로 영향을 주지 않으니까 thread 하나당 원소 하나씩 맡으면 끝난다.
이러한 병렬 연산을 GPU에서 실행하기 위해, 이제 실제 코드를 분리해보자. CUDA C는 C/C++의 확장이라 기본 문법은 같지만, 특정 함수가 어디서 실행되고 어디서 호출되는지를 명시하는 **함수 한정자(Qualifier)**가 추가된다.
| 한정자 | 실행 위치 | 호출 위치 | 특징 |
|---|---|---|---|
__global__ | Device (GPU) | Host (CPU) | GPU에서 실행될 커널(Kernel) 함수. 반드시 void 반환형을 가짐(Async 구조 때문에) |
__device__ | Device (GPU) | Device (GPU) | GPU 내부에서만 서로 호출하는 헬퍼 함수 |
__host__ | Host (CPU) | Host (CPU) | 일반적인 C/C++ 함수 (기본값, 생략 가능) global, device 키워드가 없는 함수는 모두 __host__소속이다. |
분업의 핵심: nvcc 컴파일러
하나의 소스 코드 파일(.cu) 안에 CPU 코드(main)와 GPU 코드(__global__)가 섞여 있어도 문제가 없다. NVIDIA의 전용 컴파일러인 **nvcc**가 코드를 스캔하여, 일반 코드는 표준 C 컴파일러(GCC, MSVC 등)로 넘기고, __global__이 붙은 커널 코드만 쏙 빼내어 GPU용 기계어로 따로 컴파일한다.
스레드와 블록의 갯수
Block 안 thread 총합은 1024개 이하여야 한다. 차원 분배는 자유지만 곱이 1024를 넘으면 cudaErrorLaunchOutOfResources가 뜬다. dim3(32, 32, 1)은 통과하는데 dim3(32, 32, 2)는 죽는다. z축은 따로 최대 64까지밖에 못 가는 것도 잊기 쉽다.
Grid는 훨씬 넉넉하다. x축 2³¹-1개, y/z 각 65535개까지 된다. 어지간한 데이터셋에서 이 한도 부딪힐 일은 없다.
Shared memory는 static 할당 기준 Block당 48KB까지밖에 못 쓴다. 모든 아키텍처에서 똑같다. 그 이상 쓰고 싶으면 cudaFuncSetAttribute를 호출해서 dynamic 할당으로 opt-in해야 하고, 최대치는 GPU마다 다르다 (A100 163KB, H100과 B200 227KB). 이건 입문자가 자주 모른다.
32의 배수가 아니면 손해본다
GPU는 thread를 warp 단위로 묶어서 실행한다. warp는 32개 thread고, 이 숫자는 NVIDIA GPU 모든 세대에서 고정이며 개발자가 바꿀 수 없다.
Block당 thread를 100개로 잡으면 어떻게 되냐 ,warp 4개 분량(128 thread)의 cycle을 쓰는데 실제로는 100개만 일한다. 28 slot은 빈 채로 실행되니까 28% 손해를 보고 시작하는 셈이다.
그래서 Block 크기는 보통 128이나 256, 512 중에 고른다. 256이 무난한 default라고들 한다. 더 키우면 SM 1개에 Block 하나만 올라가서 자원이 놀고, 더 작게 잡으면 scheduling overhead가 커진다.
Block 사이는 남남이다
같은 Block 안 thread끼리는 shared memory도 공유하고 __syncthreads()로 동기화도 된다. 물리적으로 같은 SM 안에 있으니까.
다른 Block끼리는 그게 안 된다. 통신도 못 하고 실행 순서 보장도 없다. Block 0이 끝나기 전에 Block 7이 먼저 끝날 수도 있다. Block 간 동기화가 필요하면 kernel을 두 번 launch해야 한다 (Hopper의 Cluster 기능을 쓰는 방법도 있는데 일단 패스한다).
이게 왜 이러냐면, Block ↔ SM 매핑이 HW 제약이라서 그렇다. shared memory를 같은 Block thread끼리 공유할 수 있는 건 물리적으로 같은 SM SRAM에 있기 때문이고, 다른 Block과 통신 못 하는 건 다른 SM이라 SRAM이 분리되어 있기 때문이다. Grid/Block/Thread 계층이 SM/warp/core 구조를 그대로 노출한 결과다.
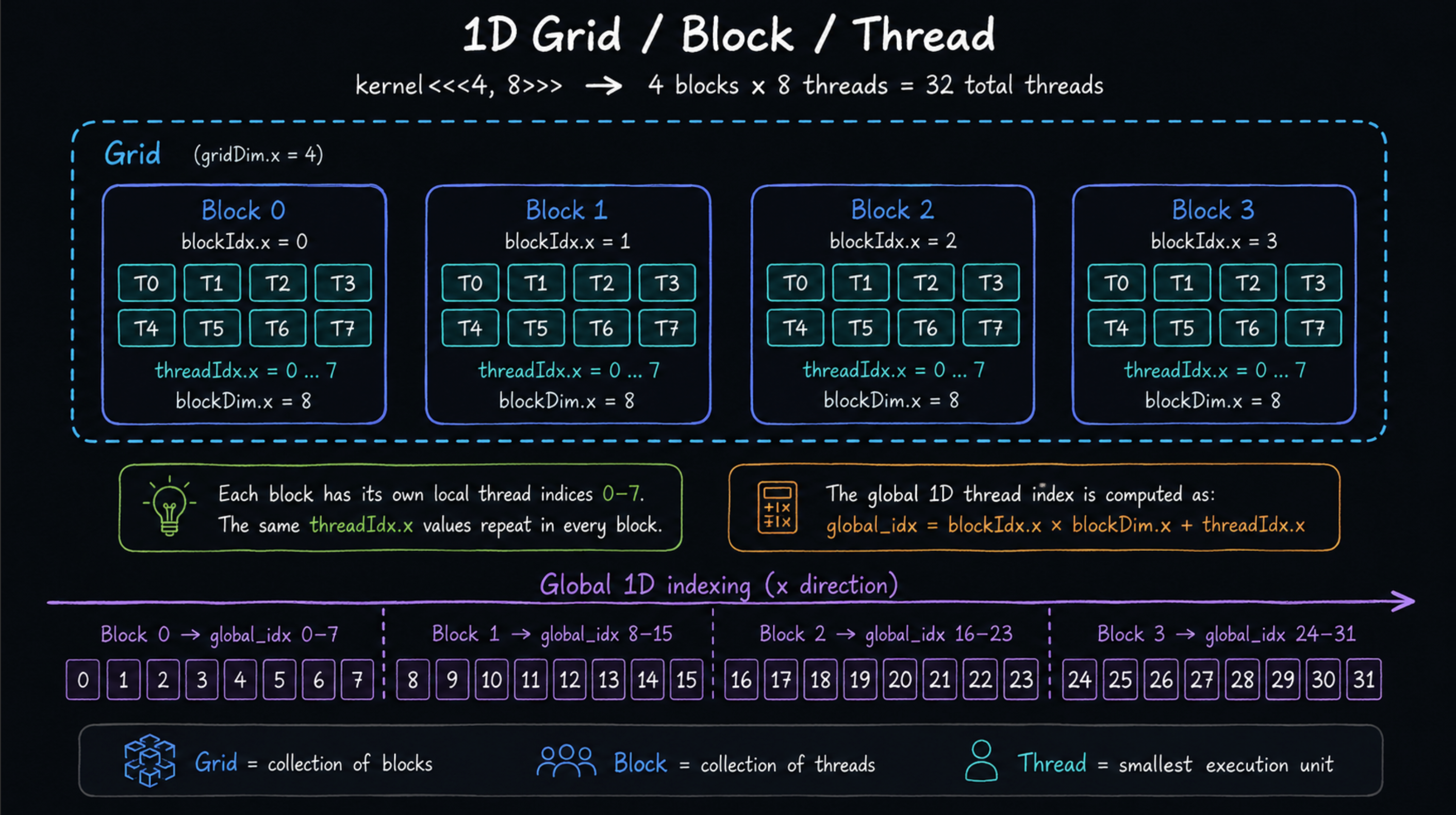
1차원 경우
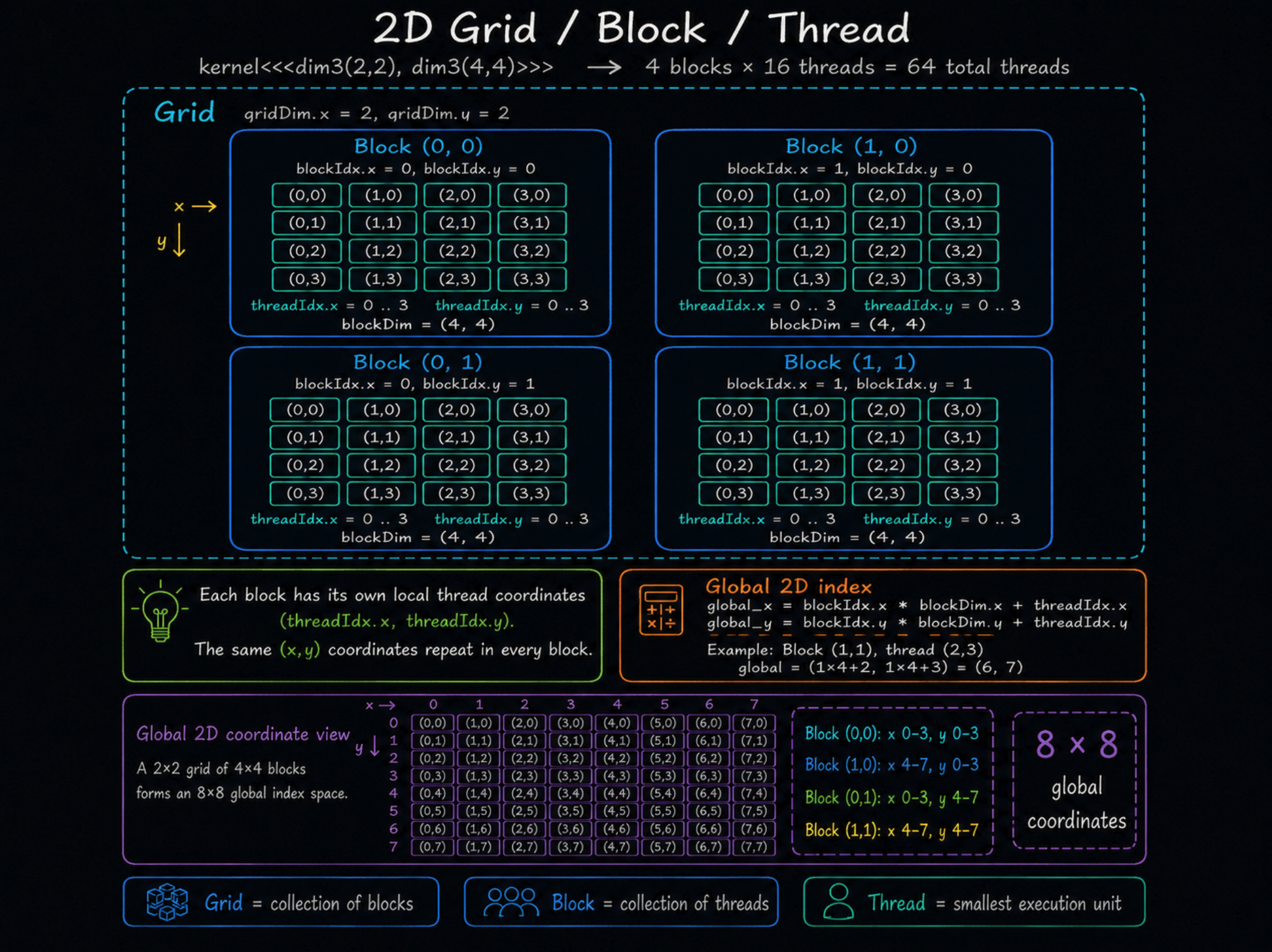
2차원 경우
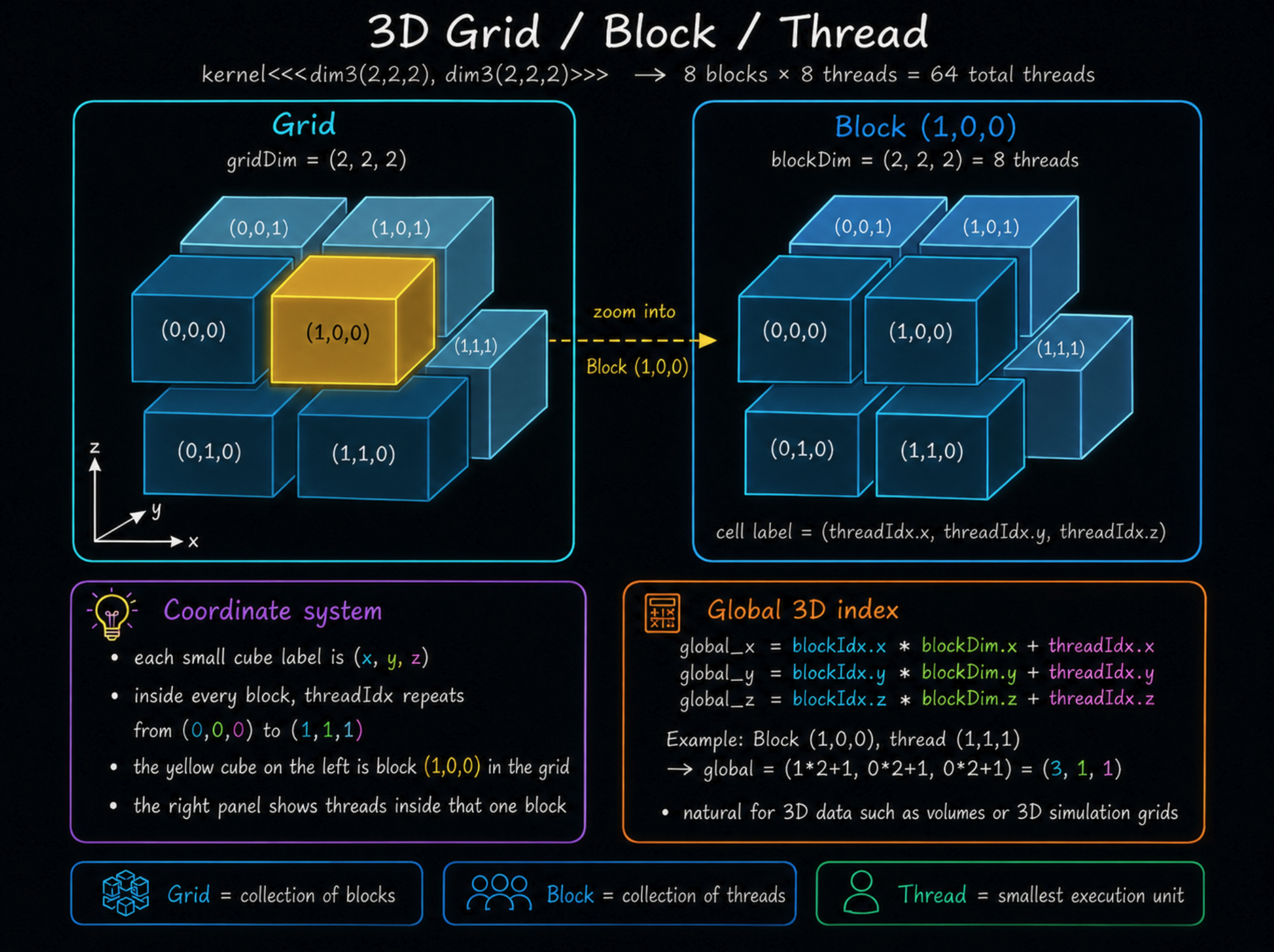
3차원 경우
Triple Chevron <<< >>> Kernel Launch 문법
__global__ 함수는 일반 함수처럼 호출하면 컴파일 에러가 난다. 반드시 triple chevron 문법을 써야 한다.
mykernel<<<gridDim, blockDim>>>(args);
// ^^^^^^^ ^^^^^^^^
// Block 개수, Block당 Thread 개수
gridDim: Grid 안에 Block이 몇 개 있는지blockDim: 각 Block 안에 Thread가 몇 개 있는지- 총 Thread 수 =
gridDim × blockDim
가장 단순한 예시:
mykernel<<<1, 1>>>(); // Block 1개, Thread 1개 → 총 1개. 사실상 순차 실행
벡터 덧셈처럼 N개 원소를 처리하려면 N개의 Thread가 필요하다. 영상에서는 단순화하여 <<<N, 1>>>로 호출하지만, 실제로는 Block당 Thread 수를 128~512개로 잡는 것이 효율적이다 (이유는 위에서 다뤘다).
int N = 10000;
int blockSize = 256;
int gridSize = (N + blockSize - 1) / blockSize; // 올림 나눗셈
add<<<gridSize, blockSize>>>(a, b, c, N);
이 <<< >>> 안의 숫자가 곧 GPU의 물리적 구조(SM, warp, block)를 그대로 노출한다는 점에 주목하자. CUDA가 다른 언어와 다르게 HW를 숨기지 않고 드러내는 대표 사례이다.